Meta-Learning
先看一下Meta-Learning和Machine-Learning的区别
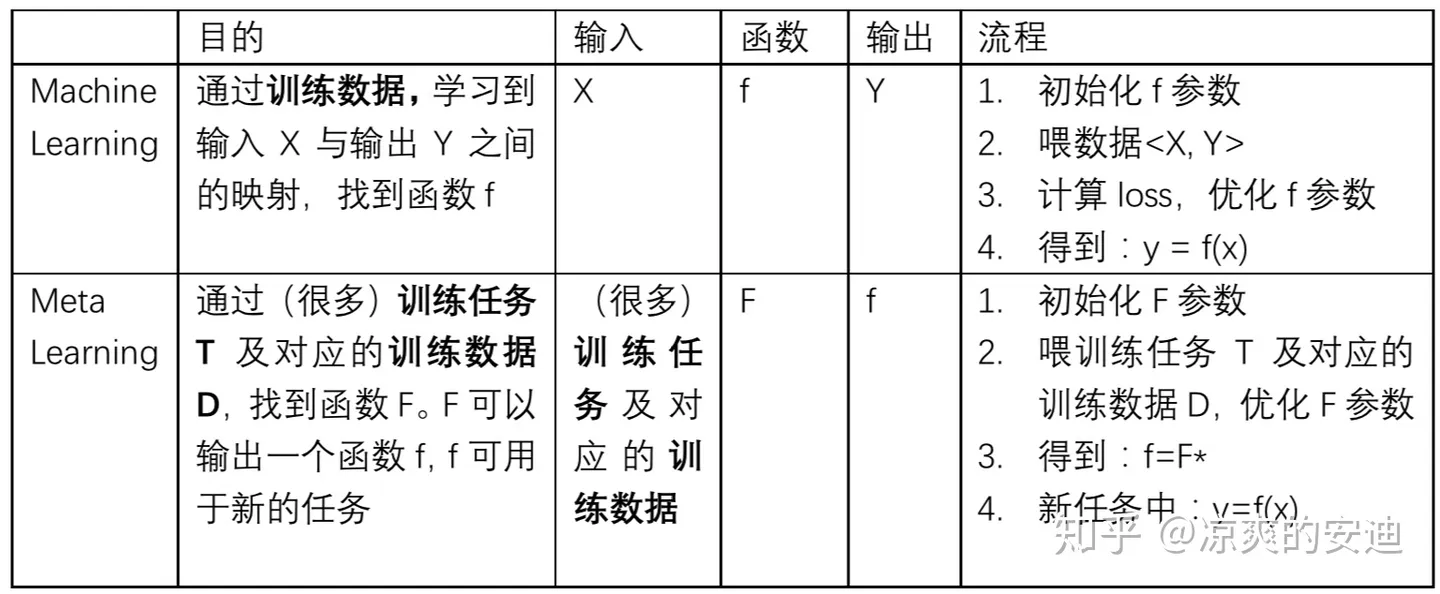
主要区别就是Meta-Learning是为了让机器学会学习,也就是通过一系列任务的训练,获取一组更好的模型初始化参数(让模型学会初始化),使其能够在小规模数据上迅速收敛并完成Fine-Tune。而传统的机器学习就是寻找当前任务的参数。
数据
元学习中要准备许多任务进行学习,每个任务都有自己的训练集和测试集。
以下为一个任务的示例:
假如要进行N-ways K-shot的图像分类任务,也就是做N个分类,每个分类下面有K张图片的任务。
我们需要构建很多个这样的任务,并且将其分为训练任务(Train Task)和测试任务(Test Task)。每个任务里面都有自己的训练数据(Support Set),测试数据(Query Set)。
用多个训练任务训练之后,在测试任务上测试性能
关键
- MAML的执行与model pretraining & transfer learning的区别?

Meta-Learning的L来源于训练任务上网络参数更新过一次之后的$\hat{\theta}^m$。基于这个$\hat{\theta}^m$使用Query Set计算该任务的loss–$l^m(\hat{\theta}^m)$并计算$l^m(\hat{\theta}^m)$对$\hat{\theta}^m$的梯度。
而model-pretraining的L来源于同一个model的参数(只有一个)使用训练数据计算loss和梯度对model进行更新,如果有多个训练任务,他的所有梯度都会直接更新到model的参数上。
直观上理解就是model-pretraining最小化当前任务上的loss,希望找到一个在许多任务上表现较好的初始化参数。而Meta-Learning最小化每一个子任务训练一步之后,第二次计算出的loss,用第二步的梯度来更新meta网络。这表明Meta希望得到参数更新的潜力(希望得到能够快速收敛的初始化参数)我们不在意$\phi$在当前Task上的表现,在意模型在$\phi$上训练出来的表现如何。
为何在meta网络赋值给具体训练任务(如任务m)后,要先更训练任务的参数,再计算梯度,更新meta网络
在更新训练任务的网络时,只走了一步,然后更新meta网络。为什么是一步,可以是多步吗?
只更新一次,速度比较快,因为Meta-Learning中子任务很多,更新多次训练时间较久
初始化参数应用到具体任务中时 可以funetuning多次
few-shot learning的训练数据往往较少
Fine-tune
初始化直接利用训练好的初始化参数
只需要抽取目标task(一个)进行学习,不用形成batch。利用目标task的support set 训练
用query set进行测试
fine-tune没有二次梯度更新 直接使用第一次梯度计算的结果更新参数。