注意变压器
Attention
心理学基础
动物在复杂环境下关注值得注意的带你
人类能够根据随意线索和不随意线索选择注意点
注意力机制的发展
首先是从传统的RNN模型得来的Encoder-Decoder(两个RNN)模型,是包含时序的($s_0$->$s_1$…)但是由于前面的所有输入$X_i$,无论多长都只能压缩成统一长度的编码c,导致翻译的精度下降。

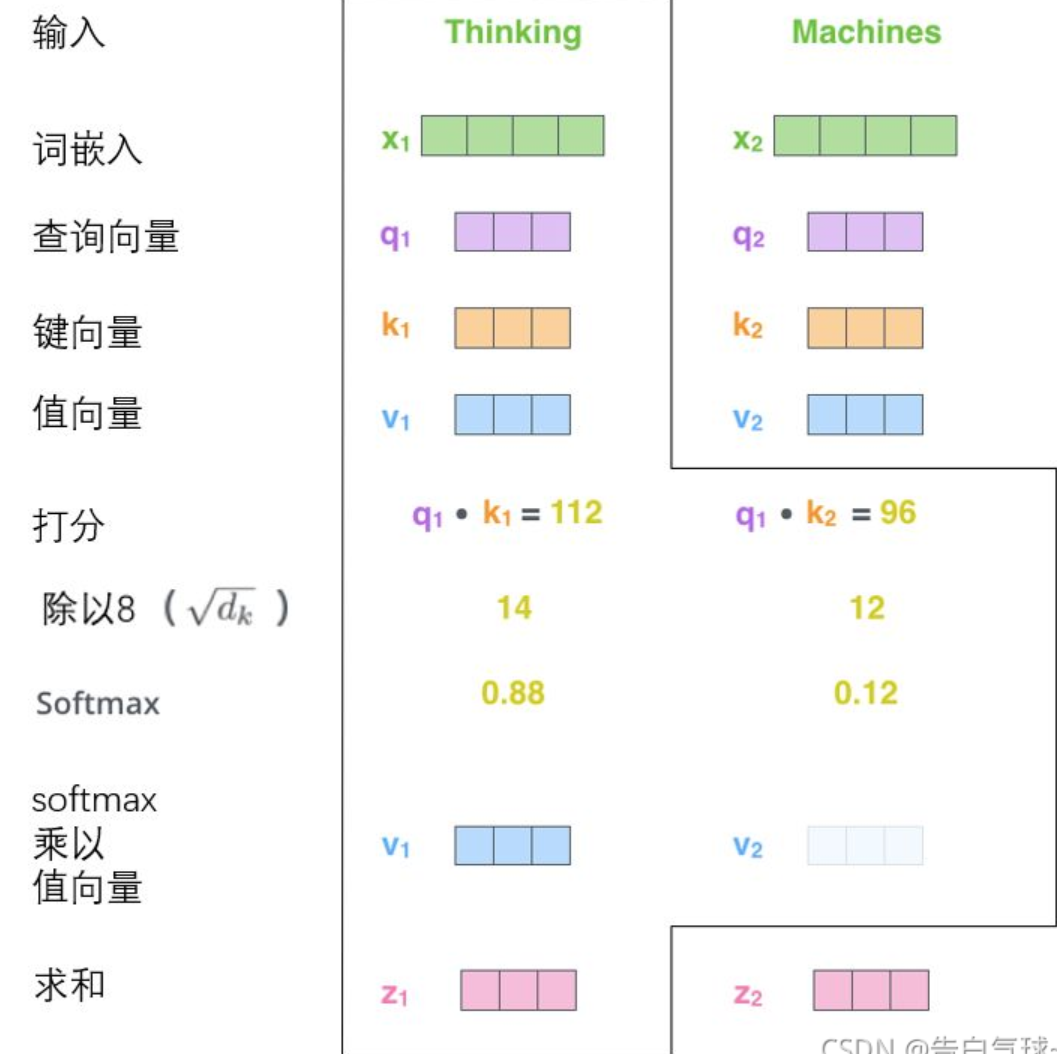
而Attention机制通过在不同时间输入不同的c来解决这个问题,而$\alpha$就是输入的权重。以$c_1$的视角来看,$\alpha_{11}\ \alpha_{12}\ \alpha_{13}$就是$c_1$对于输入$X_i$的编码$S_i$的注意力。
引入Attention之后打破了每一时刻只能用单一的编码c的限制,模型可以动态地看到全局的信息将注意力集中到对当前的任务(比如翻译)最重要的编码$s_i$上。

既然Attention机制已经对全部的输入进行打分,那RNN的时序就没什么用了,于是将时序去掉,就得到了Self-Attention。



上面是attention的公式
- 通过softmax求出权重
- 求hidden state加权和
Transformer
transformer的网络结构 由6个encoder和decoder堆叠而成

先放大其中一层的Encoder-Decoder

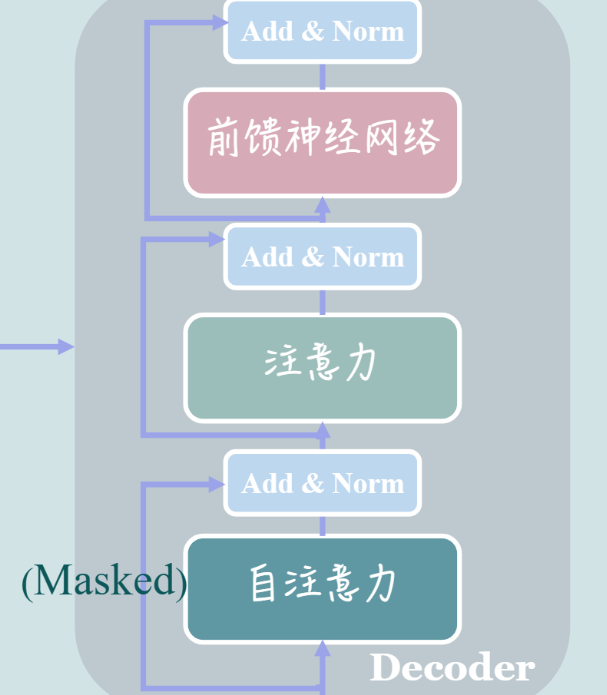
Encoder中有两个层-注意力层和前馈层
Self-Attention
首先看注意力层,下图是Self-Attention的结构:

$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$$
Query-查询,$Q=W^QX$
Key-索引,$K=W^KX$
V-内容,$V=W^VX$
都是由输入X通过线性变换得到的矩阵,其中$W^Q,W^K,W^V$都是可学习的矩阵。
为了更好地理解这三个参数,引用狗中赤兔的讲解(PS:视频太好看了 使我的attention旋转):
有一个海王,他有N个备胎,他想要从备胎中找出最符合自己期望的,分配注意力。Q表示期望,但是海外选备胎的同时,备胎也会看他的条件,用K来表示他的条件。被匹配到的备胎就是V。每个人都有自己的一套QKV,当海王开始选择自己的备胎时,备胎的K和海王的Q相似度更高的说明这个备胎更符合海王的择偶标准
$softmax(QK^T)$这个矩阵运算是在算每个行向量的相关性,softmax求得权重矩阵。
根据权重矩阵就可以得到这个海王所需要关注的备胎。也有理想型是自己的情况,这个海王最需要关心的是自己。
最后除以$\sqrt{d_k}$保持梯度稳定防止梯度消失。
结果如下:
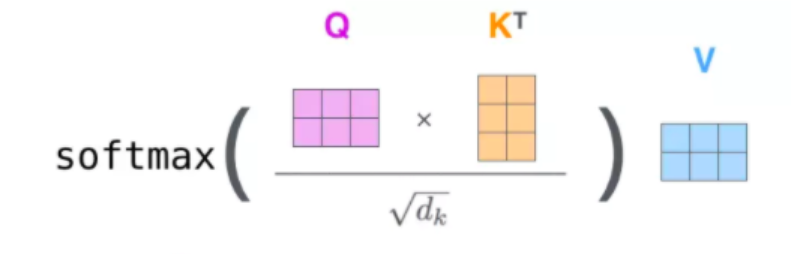
最后再与V相乘(也就是加权)就是完整的自注意力的原理。

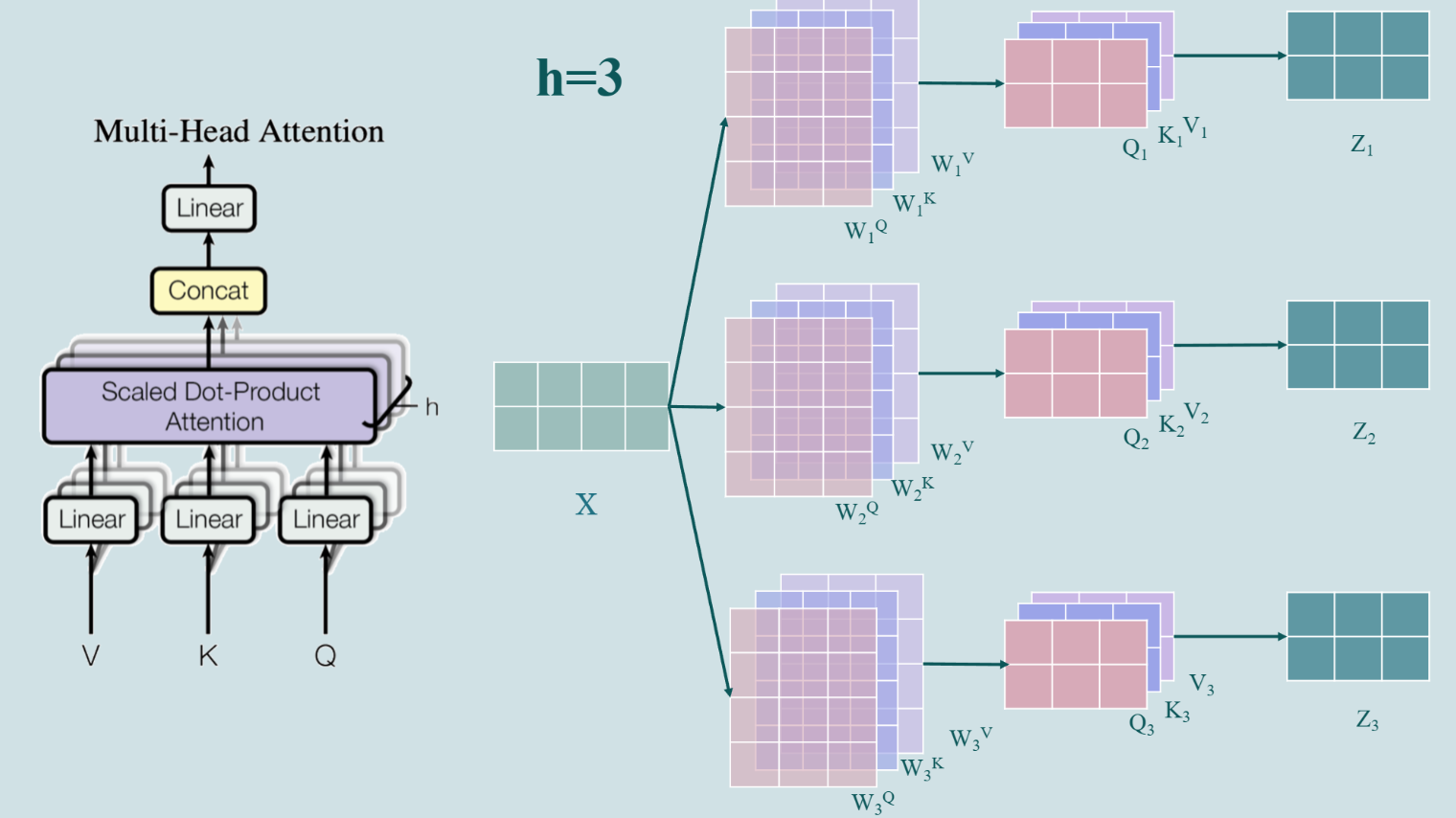
Multi-Head Attention
每个注意力头使用不同的线性变换,这意味着它们可以从输入序列的不同子空间中学习不同的特征关联。这样一来,模型可以通过多个注意力头同时关注输入序列的不同方面,例如语法结构、语义角色、主题转移等。
通过多个注意力头,模型可以学习到更丰富的上下文信息,每个头可能关注输入的不同特征,这些特征综合起来可以更全面地理解和处理输入序列。
从不同角度捕捉数据的多样性,增强了模型对复杂序列任务的理解和泛化能力。
在进行Multi-Head Attention计算之后,计算的结果需要进行 Add&Norm操作。

Add就是将当前层的计算结果和输入X相加(原理借鉴了残差网络,目的是防止退化)
Norm是layer normalization,对向量进行标准化加速收敛。
接下来放入将结果输入Feed Forward这个两层的全连接层进行特征提取,Encoder的任务就完成了。
Masked
Decoder中第一层的注意力中多了Masked
Mask的作用:1.对于长度超出期望的序列只保留期望长度的内容,未达到期望长度的填充0,填充的位置无意义,不希望分配注意力,因此给填充的位置加上负无穷。在计算注意力的时候会用到softmax函数,加上过负无穷的位置会被softmax处理为0,这个操作叫padding mask。
2.在翻译的时候需要按顺序翻译,先翻译前i个再翻译第i+1个,要阻止模型注意到还不该翻译的词,也就是每个单词之能注意到自己和自己之前的单词。
Encoder-Decoder Attention
Decoder中的第二个Multi-Head Attention并不是Self-Attention,因为他的QKV矩阵不是通过输入X得到的,K、V来自Encoder的输出Q来自Decoder第一层的输出。
Embedding
由于翻译的时候词序是很重要的,比如狗咬我和我咬狗,虽然单词一样但是顺序不同,意思也不同,而transformer没有采用RNN,难道就不能捕获序列信息了吗?
可以在Encoder外对进行Position Embedding,在将输入的文字编码成词向量的时候结合上单词的位置信息,就可以学习词序信息了。

PE是如何计算出来的呢?
$$PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})$$
$$PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})$$
$d_{model}/h=d_k=d_v$
$i\in[0,\frac{d_{model}}{2}-1]$
PE的计算结果是一个行数与序列数相等,列数与模型维度相等的矩阵–这样刚好每次取出一行来与$x_i$相加。
使用sin为偶数维度编码 cos为奇数维度编码
使用三角函数的公式

可以得到
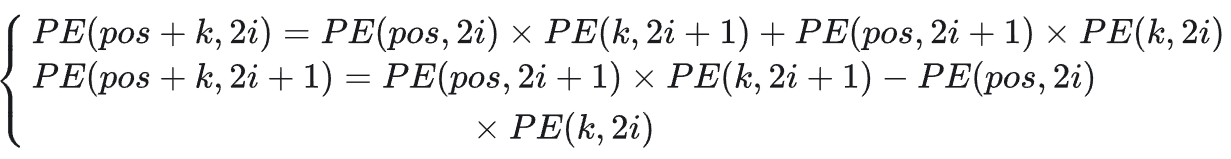
这样pos+k位置的位置向量,可以表示为pos位置和k位置的位置向量的2i与2i+1的线性组合。这就意味着位置向量中蕴含了相对位置信息。
pos=0 1 2 3 4
OutPut
做一次线性变换再通过词典输出概率最大的单词即可。
参考
Attention 机制超详细讲解(附代码) - 知乎 (zhihu.com)
解码注意力Attention机制:从技术解析到PyTorch实战_attention代码pytorch-CSDN博客
【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客
【NLP】多头注意力(Multi-Head Attention)的概念解析_多头注意力层-CSDN博客
(26 封私信 / 81 条消息) 如何理解Transformer论文中的positional encoding,和三角函数有什么关系? - 知乎 (zhihu.com)
【Transformer使我快乐(上下)】https://www.bilibili.com/video/BV1E44y1Y7B4?vd_source=1abb260791c1703ab2112e23e9c6fdd6